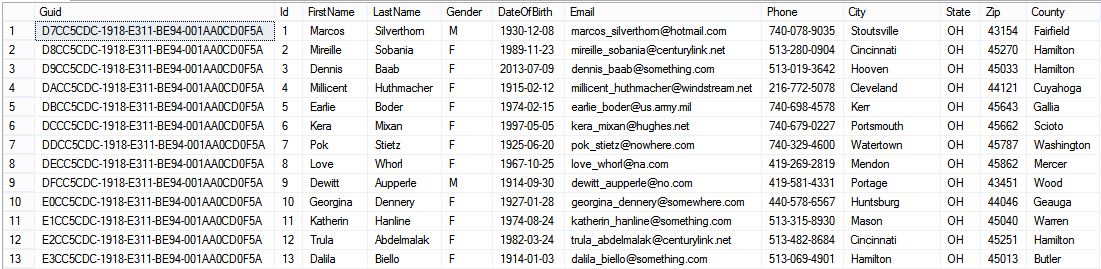
/*
Random generation of person records inserted into a [GeneratedPeople] table when [dbo].[spGeneratePeople] is executed.
The source [Address], [Domain], [First], and [Last] tables must first be populated with seed values.
*/
/*
Seed with address data
[Id] field must be a unique sequential integer
*/
CREATE TABLE [dbo].[Address](
[Id] [int] NOT NULL,
[City] [nvarchar](64) NOT NULL,
[State] [nvarchar](2) NOT NULL,
[Zip] [nvarchar](5) NOT NULL,
[County] [nvarchar](255) NOT NULL,
[AreaCode] [nvarchar](16) NOT NULL,
CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/*
Seed with domain names, e.g. google.com
[Id] field must be a unique sequential integer
*/
CREATE TABLE [dbo].[Domain](
[Id] [int] NOT NULL,
[Name] [nvarchar](100) NOT NULL,
CONSTRAINT [PK_Domain] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/*
Seed with person first names and gender
[Id] field must be a unique sequential integer
(a good source is the U.S. census)
*/
CREATE TABLE [dbo].[First](
[Id] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
[Gender] [nvarchar](1) NOT NULL,
CONSTRAINT [PK_First] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/*
Seed with person surnames
[Id] field must be a unique sequential integer
(a good source is the U.S. census)
*/
CREATE TABLE [dbo].[Last](
[Id] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
CONSTRAINT [PK_Last] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
/*
This table is created and populated with person records when the [dbo].[spGeneratePeople] procedure is executed
*/
CREATE TABLE [dbo].[GeneratedPeople](
[Guid] [uniqueidentifier] NULL,
[Id] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [nvarchar](100) NULL,
[LastName] [nvarchar](100) NULL,
[Gender] [nvarchar](2) NULL,
[DateOfBirth] [date] NULL,
[Email] [nvarchar](100) NULL,
[Phone] [nvarchar](12) NULL,
[City] [nvarchar](64) NULL,
[State] [nvarchar](2) NULL,
[Zip] [nvarchar](5) NULL,
[County] [nvarchar](255) NULL
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[GeneratedPeople] ADD DEFAULT (newsequentialid()) FOR [Guid]
GO
/*
Called by [dbo].[spGeneratePeople] to generate a birth date
*/
create procedure [dbo].[spGenerateDateOfBirth](@maxPastYears int = 100, @date date out)
as
begin
set @date = null;
if(@maxPastYears is null or @maxPastYears < 0) set @maxPastYears = 100
declare @year int = 0;
declare @value nvarchar(10) = null;
while(isdate(@value)=0)
begin
while( @year < year(getdate())-@maxPastYears or @year > year(getdate()))
select @year = case when ceiling(rand(convert(varbinary,newid())) * 2) = 1 then '19' else '20' end + right('0'+rtrim(ceiling(rand(CONVERT([varbinary],newid(),0))*(99))),(2))
declare @month int = right('0'+rtrim(ceiling(rand(CONVERT([varbinary],newid(),0))*(12))),(2))
declare @day int = right('0'+rtrim(ceiling(rand(CONVERT([varbinary],newid(),0))*(31))),(2))
set @value = convert(nvarchar(4),@year) + '-' + convert(nvarchar(2),@month) + '-' + convert(nvarchar(2),@day)
end
set @date = convert(date,@value);
return;
end
GO
/*
Called by [dbo].[spGeneratePeople] to create a subset of the records in the Address table
*/
create function [dbo].[tfGetAddresses](@state nvarchar(2) = null, @county nvarchar(255) = null, @city nvarchar(255) = null)
returns @addrs table
(
[Id] int
,[City] nvarchar(64)
,[State] nvarchar(2)
,[Zip] nvarchar(5)
,[County] nvarchar(255)
,[AreaCode] nvarchar(3)
)
as
begin
insert @addrs
select [Id] = ROW_NUMBER() OVER( ORDER BY [Zip]),[City],[State],[Zip],[County],[AreaCode]
from [Address]
where ((@state is not null and [State]= @state) or (@state is null))
and ((@county is not null and [County]= @county) or (@county is null))
and ((@city is not null and [City]= @city) or (@city is null))
return;
end
GO
/*
Generates people records into a [GeneratedPeople] table (which is dropped and re-created each time)
@number - the number of records to generate
@state - if not null, filters addresses to the two char state code
@county - if not null, filters addresses to the county
@city - if not null, filters addresses to the city
*/
create procedure [dbo].[spGeneratePeople](@number int, @state nvarchar(2), @county nvarchar(255),@city nvarchar(255))
as
begin
declare @count int = 0;
if(@number is null or @number<=0) set @number = 1
if exists (select name from sys.tables where name = 'GeneratedPeople') drop table [GeneratedPeople]
create table [GeneratedPeople]
(
[Guid] uniqueidentifier default newsequentialid()
,[Id] int identity(1,1)
,[FirstName] nvarchar(100)
,[LastName] nvarchar(100)
,[Gender] nvarchar(2)
,[DateOfBirth] date
,[Email] nvarchar(100)
,[Phone] nvarchar(12)
,[City] nvarchar(64)
,[State] nvarchar(2)
,[Zip] nvarchar(5)
,[County] nvarchar(255)
)
declare @addrs table
(
[Id] int
,[City] nvarchar(64)
,[State] nvarchar(2)
,[Zip] nvarchar(5)
,[County] nvarchar(255)
,[AreaCode] nvarchar(3)
)
insert @addrs
select *
from tfGetAddresses(@state,@county,@city)
declare @maxAddrs int = (select max([Id]) from @addrs)
declare @maxFirsts int = (select max([Id]) from [First])
declare @maxLasts int = (select max([Id]) from [Last])
declare @maxDomains int = (select max([Id]) from [Domain])
while(@count<@number)
begin
declare @date date = null
exec dbo.[spGenerateDateOfBirth] default,@date out
declare @rnd float =rand(convert(varbinary,newid()));
insert [GeneratedPeople] ([FirstName],[LastName],[Gender],[DateOfBirth],[Email],[Phone],[City],[State],[Zip],[County])
select
[FirstName] = [First].[Name]
,[LastName] = [Last].[Name]
,[Gender] = [First].[Gender]
,[DateOfBirth] = @date
,[Email] = lower([First].[Name] + '_' + [Last].[Name] + '@' + [Domain].[Name])
,[Phone] = ((((a.[AreaCode] +'-')+right('0'+rtrim(ceiling(rand(CONVERT([varbinary],newid(),0))*(999))),(3)))+'-')+right('0'+rtrim(ceiling(rand(CONVERT([varbinary],newid(),0))*(9999))),(4)))
,a.[City]
,a.[State]
,a.[Zip]
,a.[County]
from [First],[Last],[Domain],@addrs a
where [First].[Id] = (select ceiling(@rnd * @maxFirsts))
and [Last].[Id] = (select ceiling(@rnd * @maxLasts))
and [Domain].[Id] = (select ceiling(@rnd * @maxDomains))
and a.[Id] = (select ceiling(@rnd * @maxAddrs))
set @count=@count+1
end
end
GO