|
1 |
originally posted 2014-04-13 |
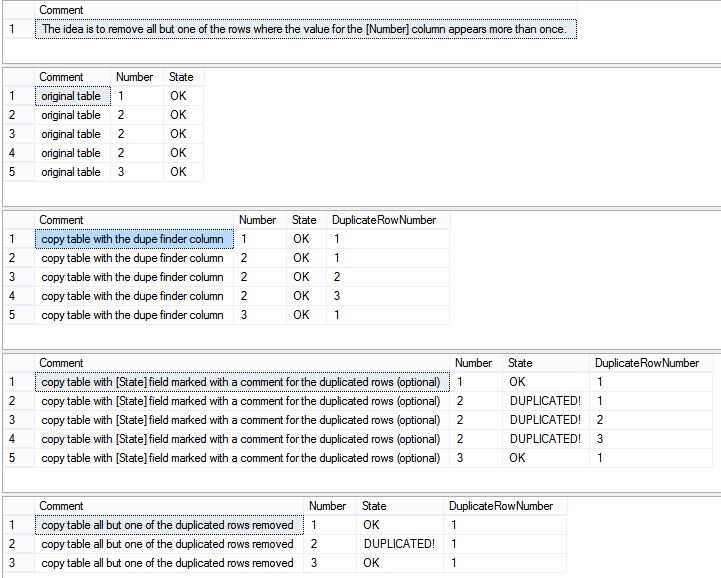
I have a query for which the keys must appear distinctly, but they are duplicated in the resultset. I want to keep only one of the duplicated rows. That is, if I find a record with a duplicated key, I want to keep only one of the records and all of its other data. I don’t care which of the rows get dumped. Admittedly, this is a strange and rare situation (all the more reason to document it).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
if (object_id('tempdb..#temp') is not null) drop table #temp create table #temp ([Number] int,[State] nvarchar(100) default 'OK') insert #temp ([Number]) values (1),(2),(2),(2),(3) select [Comment] = 'The idea is to remove all but one of the rows where the value for the [Number] column appears more than once.' select [Comment] = 'original table',* from #temp if (object_id('tempdb..#temp2') is not null) drop table #temp2 select * ,[DuplicateRowNumber] = row_number() over (partition by [Number] order by [Number]) into #temp2 from #temp select [Comment] = 'copy table with the dupe finder column',* from #temp2 update #temp2 set [State] = 'DUPLICATED!' from ( select distinct [Number] from #temp2 where [DuplicateRowNumber] > 1 ) as dupes where #temp2.[Number] = dupes.[Number] select [Comment] = 'copy table with [State] field marked with a comment for the duplicated rows (optional)',* from #temp2 delete from #temp2 where [DuplicateRowNumber] > 1 select [Comment] = 'copy table all but one of the duplicated rows removed',* from #temp2 |